
My role
Product manager (and stand-in designer)
The working team
Technical lead and 3-4 other engineers, Bendigo Bank fraud SMEs as needed
Project duration
About 1 year
The Bendigo Bank fraud investigation team had been using a third-party maintained case management system that was built seven years ago. The system is basically a series of forms that allow investigators to capture information about different types of fraud cases. The data is then used to identify patterns to prevent fraud in future.
The platform had become bloated and slow-loading (just opening a case took at least 30 seconds), and it had become a major frustration for the team. Aside from obvious operational efficiency issues, it had also caused data issues – the slowness of the system forced investigators to log data as slabs of text because it was quicker to enter these notes rather than fill in the actual form, especially when there were so many legacy fields that were no longer relevant.
Although there had been attempts to alleviate the pain with tactical solutions in the past, senior management in the fraud team was keen to solve this problem properly this time as it already clearly had such negative impact on staff costs and morale, and it was becoming impossible to keep up with increasingly strict regulations. They wanted a new platform live within 12 months.
Discovery
From a technical point of view, we were confident that whatever we build will be less laggy than the existing platform (which honestly looked like it was a relic of the early 2000s). This makes it tempting to simply do a technical “lift and shift”... but I wanted to assess whether there were other important things we needed to cover.
Research conducted
Reviewed user research videos that internal teams had recorded
Audited all the existing data fields to identify data quality problems
Interviewed data quality and data and analytics teams to identify key data pain points
Interviewed investigators from different teams to understand the variation in use cases
Observed demonstrations of how investigators used the system to understand UX pain points
Key findings
There were many superfluous fields that were no longer relevant, but were still mandatory in the forms, adding a lot of time and frustration to data entry.
On the other hand there was missing information that made it impossible to get accurate reporting numbers.
There was often incorrect validation that forced users to make up answers to irrelevant questions in order to close a case.
Unstructured text fields were used to store data because it was quicker to copy and paste a slab of text than to click through the forms.
Product vision
After this high-level discovery period, it seemed like we had enough information to set an overall direction that could drive more detailed decision-making.
The ideal state
The ideal version of this case management system would be highly efficient so that investigators can focus their energy on complex judgement tasks, not data entry and extraction.
Everything that’s able to be automated would be automated, whether it’s within this system, or between this platform and other fraud detection and management software in the ecosystem.
Data that’s captured would be used to produce live insights that would be surfaced in the investigation interfaces to support any human judgements the investigators need to make. Reporting would be a breeze.
What did this mean for our MVP?
We will ensure we deliver a snappier system with more modern UI to address the user frustrations and increase short-term operational efficiencies, but in order to set ourselves up for continued growth we need to:
design and implement more sophisticated data structures that actually correctly represent the complex data relationships in fraud cases;
revisit business requirements to make sure the data captured actually fit those requirements;
eliminate unstructured data as much as possible, as it makes aggregation and automation difficult;
ensure consistent data collection by building in smarter, dynamic forms with more specific validation.
Data design
There were two main components to the data design.
Defining data structures
Working with the tech lead, I redesigned the data structures to allow us to handle data more clearly.
Example 1 — In the existing system, there was no easy way distinguish between a scenario where an entity was involved in multiple cases under different aliases from a scenario where multiple cases that were actually related to different entities with different names. We redesigned the entity data to include a list of aliases to make this more clear.
Example 2 — In the existing system, there was no way to specify the type of relationship an entity had to a case, e.g. in scam cases, there is a perpetrator and one or more victims linked to it. This makes it difficult to assess the entity at a glance, e.g. whether someone has many cases linked to them because they are a repeat offender or a particularly susceptible victim. We introduced a property to the link between the case and each entity to make this clear.
Matching data capture to business requirements
Working with the data quality SMEs, I audited all the forms, clarifying the meaning of all the existing fields, removing any that were no longer required, structuring answers as much as possible, adding any necessary new fields to make required reporting possible.
Together we also clearly defined various dollar-figure fields that were key to business reporting so that they could be automatically calculated with minimal error and misunderstanding (and also reduced data entry time).
To future-proof the platform, we also we identified other systems that were relevant to these investigations, and ensured that the data capture patterns we used would be compatible for potential integrations.
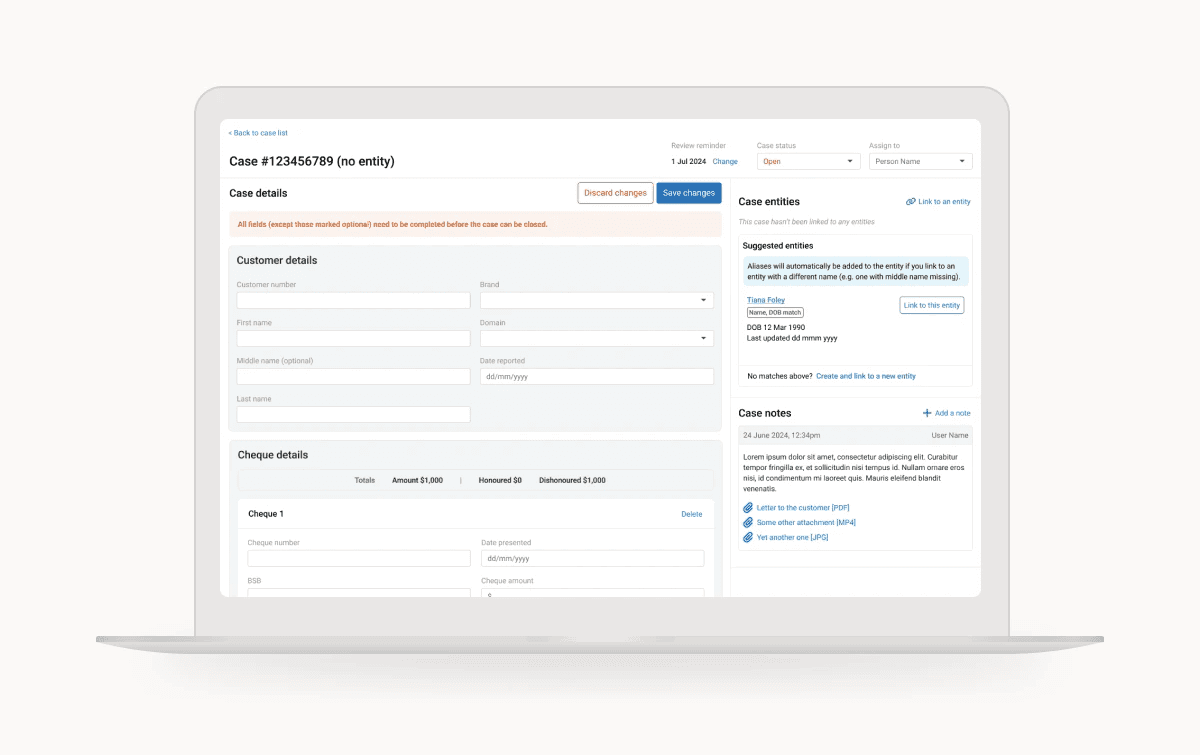
UX/UI design
In terms of interface, the key priority was to make sure the grouping of the fields made sense, that labelling was clear and consistent, and that the hierarchy and order matched the users’ mental models and operational processes.
We had no design system established, so the lead front-end engineer and I put together some high level guidelines to keep things consistent.
The design process was iterative, with multiple rounds of user testing and feedback between design and build versions – there were a lot of nuances with the cases that weren’t exposed until users saw something in front of them.
Delivery and release
The project was broken down into epics and stories so that various parts could be worked on in parallel, in an agile manner.
My involvement in the implementation included:
maintaining the Kanban board and tracking status for the work;
briefing the engineering team on each piece of work as the designs were ready;
reviewing and signing off work as it was completed by engineers;
reporting and demo-ing fortnightly to project stakeholders, working with them in any changes of priority, dates, or scope;
preparing showcase presentations for wider funding stakeholders;
preparing UAT test scripts, coordinating UAT testing with the fraud team;
suggesting release plan and collaborating with the fraud team to prepare change management for roll-out.
Results
Historical data was imported from the existing platform, and the new platform went live in May 2025. Cutover was done in one go since the old system offered no way to sync data dynamically.
The new platform has been used day to day by the fraud operations team since. Though I left the company too soon to have seen any measured results, our calculations projected that we would save the team at least 36 hours for every 1000 cases they processed.